2026.01.21 - [AI 지식정보] - AI는 어떻게 세상을 배울까? 인공지능의 과외 선생님, 데이터 라벨링
인공지능(AI)이 우리 삶의 깊숙한 곳까지 들어온 요즘, 많은 분이 "어떻게 하면 더 똑똑한 AI 모델을 만들 수 있을까?" 고민하시곤 해요. 화려한 알고리즘이나 최신 GPU 서버도 중요하지만, 사실 AI의 성패를 가르는 진짜 열쇠는 따로 있답니다. 바로 '데이터 전처리(Data Preprocessing)' 과정이에요.
혹시 'GIGO(Garbage In, Garbage Out)'라는 말을 들어보셨나요? '쓰레기가 들어가면 쓰레기가 나온다'는 뜻인데요. 아무리 뛰어난 AI 모델이라도 엉망인 데이터를 학습하면 결국 엉뚱한 결과를 내놓을 수밖에 없다는 데이터 과학의 진리죠. 오늘은 AI 학습의 첫 단추이자, 성공적인 모델 개발을 위한 필수 관문인 데이터 전처리에 대해 아주 쉽게, 그리고 깊이 있게 알아보도록 할게요.
1. AI도 편식이 필요하다? 데이터 전처리의 개념
우리가 요리를 할 때를 생각해 볼까요? 밭에서 갓 캐낸 감자나 당근을 흙이 묻은 채로 냄비에 넣는 사람은 아무도 없을 거예요. 흙을 털고, 껍질을 벗기고, 먹기 좋은 크기로 썰어야 비로소 요리 재료가 되죠.
데이터 전처리가 바로 이 과정과 똑같아요. AI가 학습하기 전에 원시 데이터(Raw Data)를 분석 가능한 형태로 깨끗하게 다듬는 과정을 말해요.
현실 세계에서 수집된 데이터는 생각보다 훨씬 지저분하답니다. 누락된 값(결측치)이 있거나, 오타 같은 오류가 섞여 있고, 똑같은 내용이 중복되기도 해요. 심지어 분석에 방해가 되는 '노이즈(Noise)'까지 포함되어 있죠. 이런 결함이 있는 데이터를 그대로 학습시키면 AI는 왜곡된 패턴을 배우게 되고, 결국 신뢰할 수 없는 결과를 초래하게 됩니다.
그래서 우리는 전처리를 통해 데이터를 수정하고 구조를 표준화해줍니다. 모델이 데이터 속에 숨겨진 의미 있는 패턴을 정확히 찾아낼 수 있도록 돕는 것이죠. 즉, 데이터 전처리는 단순한 청소 작업이 아니라, AI 학습 전반의 품질과 신뢰성을 확보하기 위한 가장 중요한 준비 과정이라고 할 수 있어요.
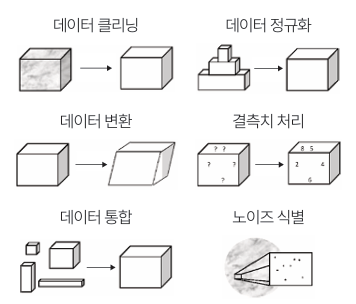
2. 완벽한 데이터를 만드는 4단계 비밀 레시피
그렇다면 데이터 전처리는 구체적으로 어떻게 진행될까요? 전문가들은 보통 이 과정을 정제, 통합, 변환, 축소의 네 단계로 나눕니다. 각 단계가 어떤 역할을 하는지 자세히 들여다볼게요.
1) 데이터 정제 (Data Cleaning)
가장 기본이 되는 단계예요. 데이터의 결함을 찾아 바로잡는 과정이죠.
- 결측치 처리: 비어 있는 값을 평균값으로 채우거나 아예 삭제합니다.
- 노이즈 식별 및 제거: 데이터의 오류나 이상치(Outlier)를 찾아내어 모델이 헷갈리지 않게 합니다.
- 오류 교정: 잘못 입력된 값이나 오타를 수정하여 데이터의 정확도를 높입니다.
2) 데이터 통합 (Data Integration)
데이터는 보통 한 곳이 아니라 여러 출처에서 모이는 경우가 많아요.
- 여러 데이터베이스나 파일에 흩어진 데이터를 하나로 합칩니다.
- 이 과정에서 서로 다른 형식이나 단위를 일관성 있게 통일시켜 줍니다. 예를 들어, 어떤 데이터는 'cm'를 쓰고 어떤 데이터는 'm'를 쓴다면 이를 맞춰주는 것이죠.
3) 데이터 변환 (Data Transformation)
AI 모델이 데이터를 더 잘 이해할 수 있도록 형태를 바꿔주는 단계예요.
- 데이터 정규화: 값의 범위를 특정 구간(예: 0~1)으로 조정해 데이터 간의 편차를 줄입니다.
- 수치화: 컴퓨터는 글자나 그림을 이해하지 못하죠? 비정형 데이터를 수치 형태로 변환해 모델이 연산할 수 있도록 만듭니다.
4) 데이터 축소 (Data Reduction)
데이터가 너무 많다고 무조건 좋은 건 아니에요. 오히려 연산 속도를 늦출 수 있죠.
- 분석에 꼭 필요한 핵심 변수만 남기고 불필요한 속성은 제거합니다.
- 전체 데이터를 대표할 수 있는 표본을 추출하여 연산 효율을 극대화합니다.
최근에는 이 복잡한 과정들을 자동화해 주는 전처리 도구와 파이프라인이 많이 도입되었어요. 덕분에 대규모 데이터셋도 빠르고 정확하게 처리하여 AI의 품질을 안정적으로 유지할 수 있게 되었답니다.
3. AI의 성패를 가르는 핵심, 왜 전처리인가?
"데이터 좀 대충 넣고 좋은 알고리즘 쓰면 안 되나요?"라고 물으실 수도 있어요. 하지만 단호하게 말씀드리면, 안 됩니다.
데이터 전처리는 AI 성능을 좌우하는 핵심 품질 관리 기술이기 때문이에요. 만약 부정확하거나 한쪽으로 치우친(편향된) 데이터가 입력된다면 어떻게 될까요? AI 모델은 잘못된 판단을 내리거나, 새로운 데이터에는 적응하지 못하는 '과적합(Overfitting)' 문제를 일으킬 수 있어요. 심지어 사회적으로 민감한 이슈에 대해 공정하지 못한 결과를 내놓을 수도 있죠.
따라서 전처리를 통해 데이터의 정확성과 다양성을 확보하는 일은 단순한 기술적 절차를 넘어, AI의 신뢰성과 책임성을 높이는 필수적인 과정입니다.
또한, 잘 정돈된 데이터는 이후에 이어질 데이터 랭글링, 라벨링, 피처 엔지니어링 같은 후속 과정의 효율을 엄청나게 높여줍니다. 결국 전처리에 들인 시간과 노력은 AI 개발 전반의 자동화와 품질 향상이라는 달콤한 열매로 돌아오게 되는 것이죠.

요약: 데이터 전처리는 선택이 아닌 필수
오늘 우리는 데이터 전처리가 무엇인지, 그리고 왜 AI 개발에서 가장 중요한 단계로 꼽히는지 살펴보았습니다.
원시 데이터의 누락값과 잡음을 제거하는 정제, 흩어진 정보를 모으는 통합, 모델이 이해하기 쉽게 바꾸는 변환, 그리고 효율을 높이는 축소까지. 이 모든 과정이 어우러져야 비로소 AI는 제대로 된 학습을 할 수 있습니다.
화려한 인공지능 기술 뒤에는 언제나 묵묵히 데이터를 닦고 조이는 '전처리' 과정이 있다는 사실, 꼭 기억해 주세요. 좋은 재료가 최고의 요리를 만들듯, 좋은 데이터 전처리가 최고의 AI를 만듭니다.
'AI 지식정보' 카테고리의 다른 글
| AI가 점점 똑똑해지는 진짜 이유? '매개변수' 3분 만에 이해하기 (1) | 2026.01.22 |
|---|---|
| 코딩 몰라도 앱을 만든다고? 개발의 판을 뒤집는 '로우 코드' (0) | 2026.01.22 |
| AI는 어떻게 세상을 배울까? 인공지능의 과외 선생님, 데이터 라벨링 (1) | 2026.01.21 |
| 'AI가 뇌를 복사했다?' 전력 소모를 획기적으로 줄이는 뉴로모픽 컴퓨팅 (0) | 2026.01.21 |
| '이 사진 속 글자, 어떻게 읽었지?' 종이 서류를 디지털로 순간 이동시키는 OCR (1) | 2026.01.21 |



