2026.01.20 - [AI 지식정보] - "AI가 거짓말을 안 한다고?" 챗GPT의 한계를 뛰어넘는 RAG 기술
2026.01.18 - [AI 지식정보] - LLM이 도대체 뭐길래?
엄청난 스펙을 가진 신입 사원이 입사했다고 상상해 보세요. 명문대를 졸업하고 아는 것도 정말 많습니다. 그런데 막상 일을 시켜보니 우리 회사에서만 쓰는 용어를 하나도 못 알아듣고, 보고서 양식도 제멋대로라면 어떨까요? 아무리 똑똑해도 당장 실무에 투입하기는 어렵겠죠.
지금 우리가 접하는 거대 언어 모델(LLM)들이 딱 이런 상태입니다. 세상의 모든 지식을 배웠지만, 정작 내가 필요한 '특정한 일'에는 서툰 경우가 많습니다. 바로 이 똑똑한 AI에게 우리만의 규칙과 스타일을 가르치는 과정, 그것이 바로 '미세조정(Fine-Tuning, 파인튜닝)'입니다. 오늘은 AI를 진정한 내 편으로 만드는 핵심 기술, 미세조정에 대해 아주 쉽게 풀어드릴게요.
미세조정(Fine-Tuning), AI를 전문가로 만드는 '맞춤 교육'
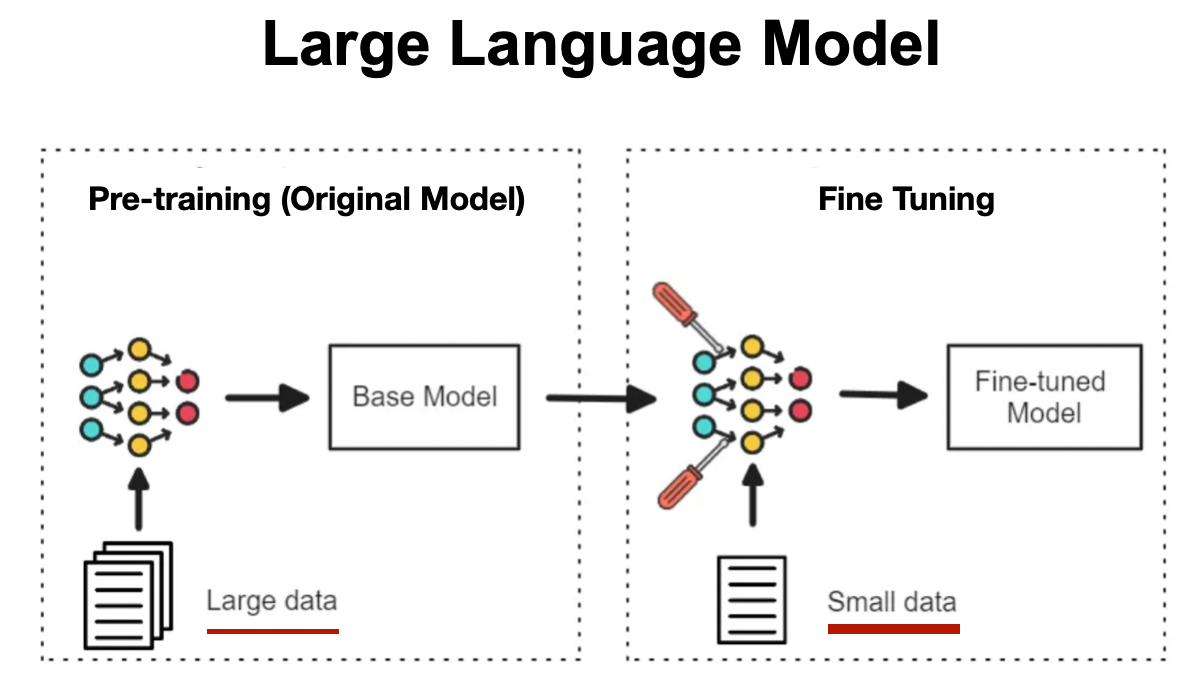
미세조정이란 이미 방대한 데이터로 사전 학습(Pre-training)을 마친 AI 모델을, 새로운 목적이나 특정 환경에 딱 맞게 다시 한번 가르치는 과정을 말합니다.
쉽게 말해, '일반 교양'을 마친 AI에게 '전공 심화 학습'이나 '신입 사원 직무 연수(OJT)'를 시키는 것과 같습니다. 기존에 AI가 가지고 있던 언어 능력이나 일반 상식은 그대로 유지하면서, 의학, 법률, 코딩, 혹은 우리 회사의 고객 응대 매뉴얼 같은 새로운 데이터의 특성을 반영해 모델의 행동을 재정렬하는 기술이죠.
최근 챗GPT 같은 LLM이 발전하면서 이 기술은 더욱 중요해졌습니다. 단순히 정답률을 높이는 것을 넘어, AI의 말투(페르소나)를 바꾸거나, 추론하는 방식을 교정하고, 답변의 안전성 기준을 세우는 등 모델을 우리가 원하는 방향으로 정교하게 다듬는 핵심 단계로 자리 잡았습니다.

다 바꾸거나, 살짝만 고치거나 (미세조정의 과정)
그렇다면 이미 다 큰 AI를 어떻게 다시 가르칠까요? 크게 두 가지 방법이 있습니다.
1. 풀 미세조정 (Full Fine-Tuning): 집 전체 리모델링
모델이 가진 모든 매개변수(Parameter, 뇌세포라고 생각하세요)를 새로운 데이터에 맞춰 처음부터 다시 학습시키는 방식입니다. 효과는 가장 강력하지만, 돈과 시간이 어마어마하게 듭니다. 게다가 너무 새로운 것만 가르치다 보면, 예전에 배웠던 일반 지식을 까먹어버리는 '지식 파괴(Catastrophic Forgetting)' 현상이 일어날 위험도 있습니다. 그래서 요즘처럼 모델이 거대해진 시대에는 잘 쓰이지 않는 방식입니다.
2. PEFT (Parameter-Efficient Fine-Tuning): 인테리어만 살짝 변경
요즘 산업계와 연구실에서 가장 사랑받는 방식입니다. 모델의 대부분은 "건드리지 마!" 하고 고정(Freeze)시켜 두고, 극히 일부의 매개변수만 살짝 조정하거나 새로운 연산 층을 덧붙이는 방식입니다.
대표적으로 LoRA(Low-Rank Adaptation)라는 기술이 있는데요, 이는 거대한 모델을 통째로 재학습하는 대신, 옆에 작은 보조 장치를 달아서 학습시키는 것과 비슷합니다.
- 장점: 연산 비용이 확 줄어들고, 원래 모델의 똑똑함은 유지하면서 특정 능력만 강화할 수 있습니다. 소량의 고품질 데이터만 있어도 AI에게 특정 말투나 전문 지식을 주입하기 딱 좋죠.
- 주의점: 아무리 효율적이라도 특정 작업에만 너무 과몰입하게 되면, 일반적인 대화 능력이 조금 떨어질 수도 있습니다. 그래서 데이터의 품질과 튜닝 범위를 잘 조절하는 것이 기술력의 핵심입니다.
왜 그냥 쓰면 안 되고 '미세조정'을 해야 할까요?
"그냥 똑똑한 챗GPT한테 프롬프트(명령어)만 잘 입력하면 되는 거 아니야?"라고 생각하실 수도 있습니다. 물론 간단한 작업은 그럴 수 있습니다. 하지만 비즈니스 환경에서는 이야기가 다릅니다.
사전 학습된 모델은 '범용성'을 목표로 만들어졌기 때문에, 특정 도메인의 전문 용어나, 우리 회사만의 독특한 문서 구조, 혹은 까다로운 법적 규제 사항을 알지 못합니다. 예를 들어, 금융권 AI라면 고객에게 상품을 추천할 때 법적으로 문제가 될 만한 발언은 절대 해서는 안 되겠죠.
이때 미세조정이 '간극(Gap)'을 메워주는 역할을 합니다.
- 맞춤형 서비스: 고객 응대 스타일을 우리 브랜드 톤앤매너에 맞게 통일할 수 있습니다.
- 오작동 감소: 엉뚱한 거짓 정보를 말하는 환각(Hallucination) 현상을 줄이고, 전문 지식에 기반한 정확한 답변을 유도합니다.
- 보안과 경쟁력: 우리 회사의 내부 데이터를 학습시켜, 외부 모델은 절대 흉내 낼 수 없는 독자적인 경쟁력을 갖춘 시스템을 구축할 수 있습니다.
결국 LLM 시대에 미세조정은 선택이 아닌, 실질적인 성과를 내기 위한 필수 코스가 되었습니다.
마무리하며
미세조정(Fine-Tuning)은 거대한 AI라는 원석을 갈고닦아, 나에게 꼭 맞는 보석으로 만드는 과정입니다. 아무리 좋은 도구도 내 손에 맞지 않으면 쓸모가 없듯이, AI도 우리 조직과 업무의 맥락을 이해해야 비로소 진가를 발휘합니다.
이제 AI 도입을 고민하고 계신다면, 단순히 "어떤 모델을 쓸까?"를 넘어 "우리 데이터로 어떻게 미세조정해서 차별화할까?"를 고민해야 할 시점입니다.
'AI 지식정보' 카테고리의 다른 글
| 챗GPT보다 똑똑한 전문가? 버티컬 AI(Vertical AI)가 돈이 되는 이유 (1) | 2026.01.28 |
|---|---|
| 코딩 몰라도 개발자가 된다고? AI 시대의 새로운 흐름, '바이브 코딩' (7) | 2026.01.27 |
| AI와 내 컴퓨터의 완벽한 소통법, MCP(Model Context Protocol) (0) | 2026.01.25 |
| AI도 다이어트가 필요해? 성능은 그대로, 몸집만 줄이는 '모델 압축' (0) | 2026.01.25 |
| 데이터의 꼬리표? AI 시대에 '메타 데이터'가 중요한 이유 (0) | 2026.01.25 |



