2026.02.08 - [AI 지식정보] - 챗GPT 과금의 기본 단위 '토큰(Token)'에 대해
2026.01.18 - [AI 지식정보] - LLM이 도대체 뭐길래?
인공지능(AI)이 그림도 그리고, 소설도 쓰고, 심지어 코딩까지 해주는 세상입니다. 혹시 이런 생각 해보신 적 없나요? "도대체 하나의 AI가 어떻게 이렇게 다양한 일을 전부 다 잘할 수 있을까?" 예전에는 바둑 두는 AI는 바둑만 두고, 번역하는 AI는 번역만 했었는데 말이죠.
그 비밀의 열쇠가 바로 오늘 소개할 파운데이션 모델(Foundation Model)입니다. 건물을 지을 때 튼튼한 기초(Foundation)가 필요하듯, 지금의 AI 전성시대를 연 가장 핵심적인 기반 기술이라고 할 수 있습니다. 오늘은 이 개념이 무엇인지, 그리고 앞으로의 AI 시장을 어떻게 바꿔놓을지 아주 쉽게 풀어서 설명해 드릴게요.
1. 모든 AI의 기초 공사, 파운데이션 모델이란?
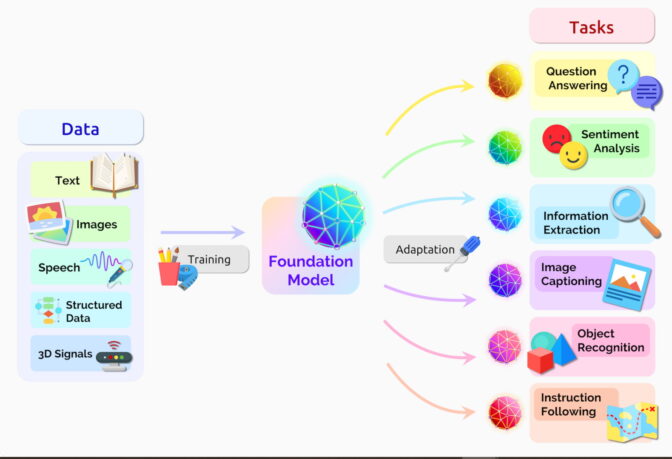
파운데이션 모델은 말 그대로 거대한 '기반'이 되는 모델을 뜻합니다. 방대한 양의 데이터를 미리 학습해서, 특정 용도가 아닌 '범용적'인 능력을 갖춘 AI 모델을 말하죠.
과거의 AI 개발 방식을 '주문 제작형 가구'라고 한다면, 파운데이션 모델은 '레고 블록 세트'와 같습니다.
- 기존 AI: 번역을 위해 번역 데이터만 학습하고, 얼굴 인식을 위해 얼굴 사진만 학습했습니다. 하나를 잘하지만 다른 건 전혀 못 했죠.
- 파운데이션 모델: 인터넷상의 거의 모든 텍스트, 이미지, 음성 데이터를 통째로 학습합니다. 언어의 규칙, 사물의 생김새, 소리의 패턴 등 '세상의 일반적인 지식'을 미리 익혀두는 것입니다.

이렇게 구축된 거대한 모델 하나만 있으면, 약간의 조정만으로 번역기도 만들고, 챗봇도 만들고, 분석기도 만들 수 있습니다. 즉, 하나의 모델이 수많은 AI 서비스의 뿌리 역할을 하는 셈입니다. 우리가 잘 아는 GPT나 제미나이(Gemini) 같은 모델들이 바로 대표적인 파운데이션 모델입니다.
2. 수조 개의 데이터를 읽다: 작동 원리와 특징
그렇다면 이 모델은 어떻게 만들어질까요? 핵심은 '사전 학습(Pre-training)'과 '미세 조정(Fine-tuning)'이라는 두 가지 단계에 있습니다.
2-1. 스스로 패턴을 찾는 거대한 뇌
파운데이션 모델은 주로 '트랜스포머(Transformer)'라는 신경망 구조를 사용해 수조 개에 달하는 단어와 이미지를 학습합니다. 이때 사람이 일일이 "이건 고양이야", "이건 사과야"라고 가르쳐주지 않아도 됩니다. (이를 자기지도 학습이라고 해요.)
모델은 방대한 데이터 속에서 스스로 패턴을 찾아냅니다. "아, '배고파'라는 단어 뒤에는 '밥 먹자'라는 말이 자주 나오는구나", "강아지 사진에는 보통 귀가 두 개 있구나" 하는 식이죠. 이렇게 데이터 간의 관계를 스스로 파악하며 일반적인 지능을 갖추게 됩니다.
2-2. 하나를 배우면 열을 아는 적응력
이렇게 기초 체력을 튼튼하게 다진 모델은 미세 조정(Fine-tuning)을 통해 전문가로 변신합니다.
이미 언어를 이해하고 있기 때문에, 법률 데이터만 조금 더 공부시키면 'AI 변호사'가 되고, 의학 논문을 보여주면 'AI 의사'가 될 수 있는 것이죠. 처음부터 다시 만들 필요 없이, 이미 있는 파운데이션 모델에 숟가락만 얹으면 되니 효율성이 엄청나게 높아집니다.
3. AI 개발의 판도를 바꾼 영향력과 한계
파운데이션 모델의 등장은 AI 산업의 패러다임을 완전히 뒤집어 놓았습니다.
3-1. 긍정적 효과: 누구나 AI를 만드는 세상
예전에는 고성능 AI를 만들려면 막대한 데이터와 시간이 필요했습니다. 하지만 이제는 구글이나 오픈AI가 만들어둔 파운데이션 모델을 API 형태로 빌려와서, 우리 회사만의 서비스를 뚝딱 만들 수 있게 되었죠. 스타트업이나 개인 개발자도 혁신적인 AI 앱을 빠르게 출시할 수 있게 된 배경입니다.
3-2. 우려되는 점: 동전의 양면
하지만 빛이 있으면 그림자도 있는 법입니다.
- 비용과 에너지: 모델이 너무 크다 보니 학습시키는 데 천문학적인 비용과 전력이 소모됩니다.
- 블랙박스 문제: 모델이 내부적으로 어떻게 판단을 내리는지 개발자조차 완벽하게 이해하기 어렵습니다.
- 편향성: 학습 데이터에 혐오 표현이나 잘못된 상식이 섞여 있다면, 이를 기반으로 만든 모든 서비스가 오염될 수 있습니다.
- 독점: 막대한 자본이 필요하다 보니, 소수의 빅테크 기업만이 이 모델을 소유하고 통제할 가능성이 큽니다.
글을 마치며
결국 파운데이션 모델은 현대 AI의 심장이자, 다가올 미래 기술의 인프라입니다. 전기가 발명되고 나서 모든 산업이 바뀌었듯이, 이 거대한 모델 위에 어떤 새로운 서비스들이 쌓이느냐에 따라 우리의 삶은 또 한 번 크게 달라질 것입니다.
'AI 지식정보' 카테고리의 다른 글
| 똑같은 AI인데 왜 결과가 다를까? 돈이 되는 '프롬프트(Prompt)' 엔지니어링의 비밀 (0) | 2026.02.22 |
|---|---|
| 공장 하나 없이 전 세계 반도체 시장을 지배한다고? '팹리스(Fabless)' (0) | 2026.02.22 |
| 챗GPT 과금의 기본 단위 '토큰(Token)'에 대해 (1) | 2026.02.08 |
| 데이터가 너무 많아서 AI가 바보가 된다고? '차원의 저주' (3) | 2026.02.05 |
| 배우지 않아도 정답을 맞히는 AI? 제로샷 러닝(Zero-shot Learning) (1) | 2026.02.04 |



